Journey to multi-tenancy at scale with Elasticsearch
By: Di Hu and Udbhav Prasad
Stairwell enables security teams to search for and identify malicious files in near real-time, both in their environment and in the wild. To achieve this, files are continuously ingested into the Stairwell platform. Stairwell retains a permanent copy of the files, extracting a wealth of metadata and performing continuous and comprehensive analysis. These files and the generated insights can only be surfaced with powerful search that supports a versatile syntax, continuous updates, and a large data volume.
This blog outlines our journey in developing the search for the Stairwell platform, specifically using Elasticsearch, detailing the scalability and operational challenges we encountered and how we overcame them.
Background
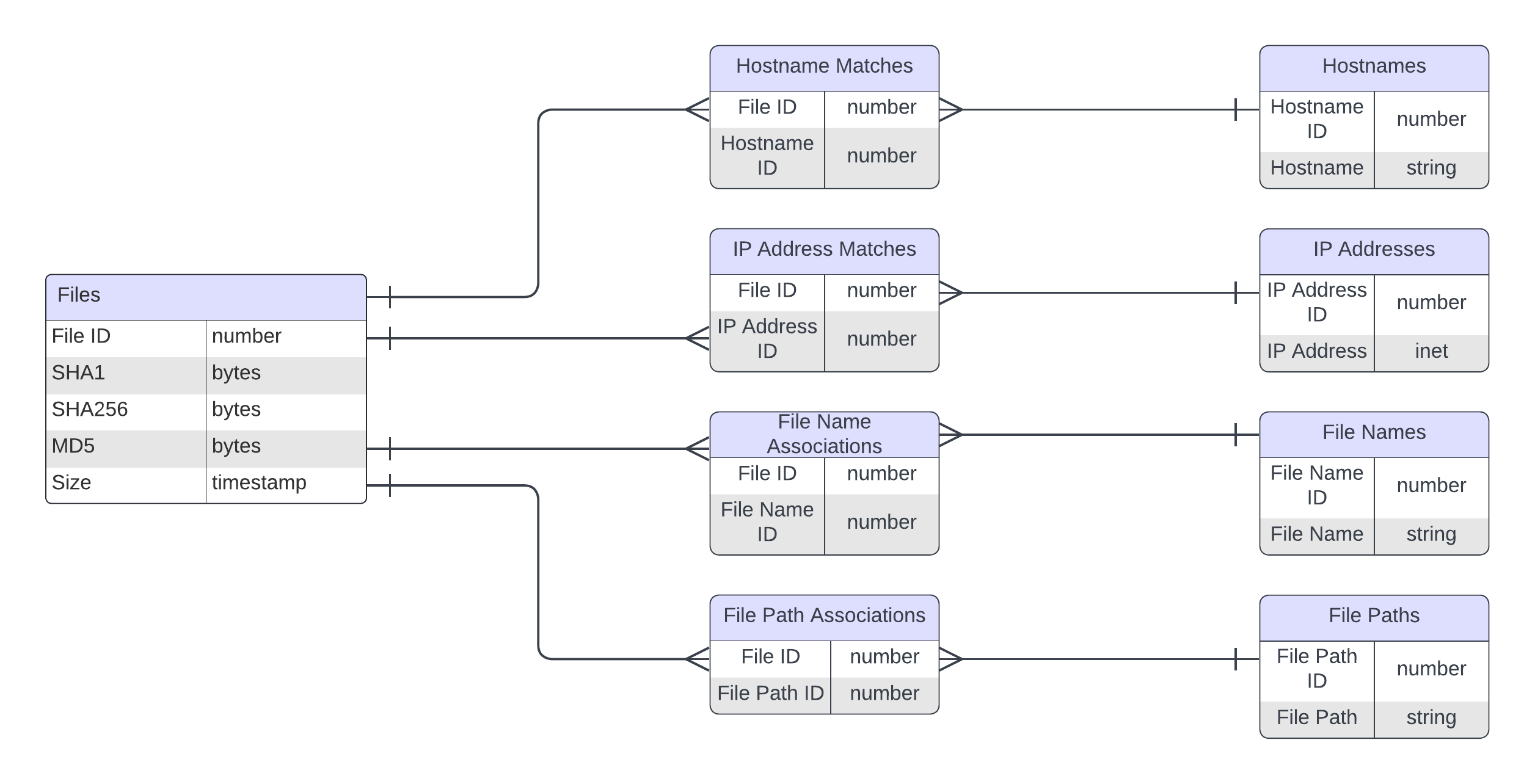
Our initial architecture stored file metadata and analysis results in a SQL database in a normalized format. Searching for file matches involved creating secondary indexes on the relevant columns and joining several tables.
As Stairwell’s customer base rapidly grew, we faced scalability challenges. To support ever-growing enterprise-sized data and more complex search queries, we required a dedicated reverse index to manage the large volumes of metadata and high ingestion and search throughputs.
We chose Elasticsearch and opted to self-host our cluster using Elastic on Kubernetes (ECK).
Search and Indexing Infrastructure
In the new infrastructure, an event is broadcast for newly ingested files, file sightings, user-driven actions, and analysis results, which are then consumed by an indexer service that writes metadata to Elasticsearch. User searches are handled by a query server that translates Common Expression Language into Elasticsearch payloads.
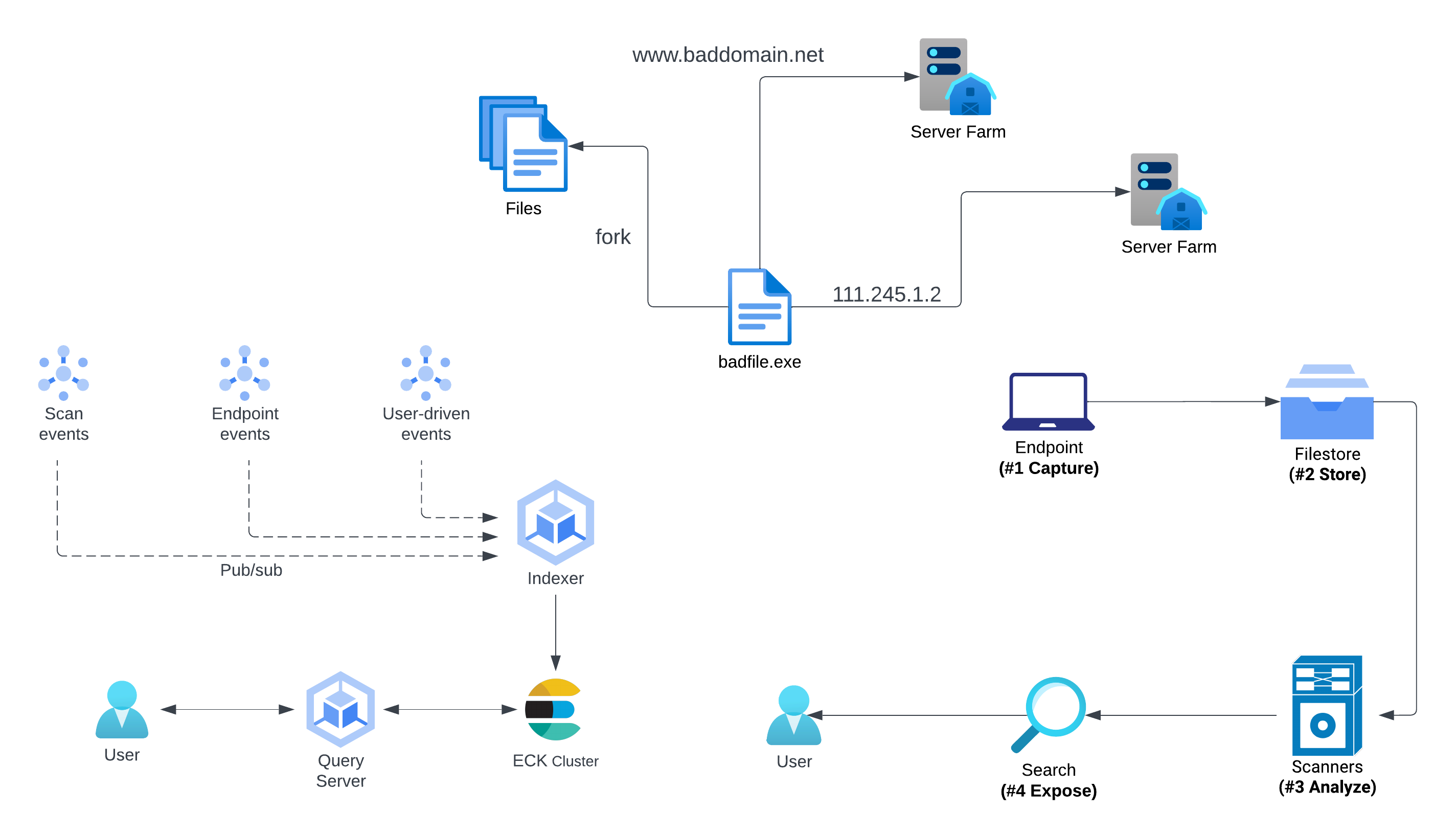
Elastic Index Design
Unique to Stairwell is the data model that allows users to share files and analysis with other organizations within the platform. Our threat researchers extensively use this model to create and maintain malware feeds which are accessible to all customers to help them detect and respond to malware.
With this in mind, we evaluated several index designs but narrowed it down to two approaches; single indexing and splitting data across multiple indexes:
Approach #1: Single Index for all Files
A single Elasticsearch index for all file metadata has several benefits:
- No duplication of shared file metadata
- Simplicity in indexing logic, avoiding repeated updates for occurrences of the same file over time
- Simplicity in search logic, avoiding the need to merge and deduplicate results across multiple indexes
- Low overhead in index management – schema and config changes are reflected to all customers

Supporting new search types on the platform would simply involve adding the appropriate fields to the index and updating the corresponding indexing and search code.
We identified several drawbacks when this is evaluated at scale:
Shard Sizing
The number of shards cannot be changed after the index has been created. The only option for altering the number of shards is to split the existing index, a process that requires putting the index into read-only mode.
As Stairwell continuously ingests new files and as more metadata and analysis are indexed into the cluster, the index inevitably grows larger. This growth will inevitably lead to a decline in both search and indexing performance over time. Moreover, search latencies increase, adversely affecting all customers, regardless of the volume of files they have uploaded to the platform.
Backfill
When new fields are added to the schema, we need to backfill data for existing documents, which can be done with Elasticsearch’s bulk indexing API. However, since indexing and search workloads compete for resources on the same nodes, going full throttle on backfill affects search latencies. Initially, this might not be a challenge since a backfill could finish overnight, but as the number of documents grows, backfills would take increasingly longer.
Nested Fields
Nested fields are stored as separate documents, and are known to slow down search and indexing speeds. Customer-specific metadata like endpoint details and file sightings needs to be stored in nested fields to preserve associations. Since this metadata is updated and queried frequently, we were keen to keep the index structure as flat as possible.
Data Commingling
If all file metadata lived on the same index, we would need an extra user authorization clause with every query to ensure a customer was only able to see files that were accessible to them. In addition to potential data leak and security risks, this was not aligned with our strategy of avoiding the commingling of data.
Approach #2: Split Data Across Multiple Indexes
Having a monolithic index requires each search query to sift through all the shards in the index, and this is likely to keep growing until it becomes impossible to scan everything since the total amount of data is too large. A natural improvement is to reduce the search space by splitting the data into multiple indexes.
We considered a few strategies for this approach:
- A separate Elastic cluster for each customer
- A separate index for each customer, with all indexes living on the same or multiple clusters
- A mixed strategy where large customers get their own index, and small customers share a common index
- Custom search shard routing
Stairwell’s direct customers create an environment to upload their files and our managed service partners create new environments for their end customers at any time. We also create a lot of demo customer environments which have very little to no data, so it’s very slow and wasteful to create a separate Elastic cluster (option #1) for each customer. For similar reasons, since our shards grow so quickly, search shard routing (#4) also isn’t suitable.
We settled on creating a separate index (#2) for each customer, since it’s operationally much simpler than mixed indexes (#3). Compared to approach #1, all searches still share resources on the same cluster, but occasionally migrating some indexes to a new cluster was more feasible than creating a new cluster for each index.
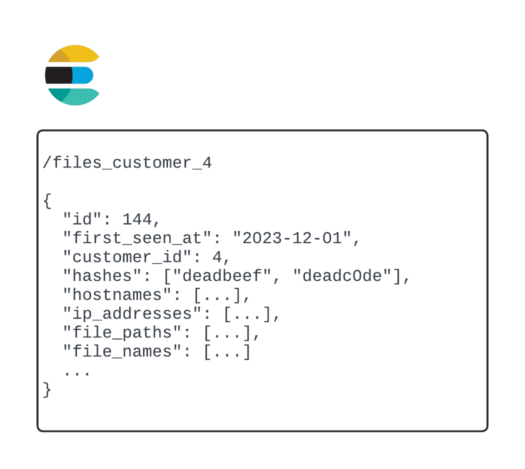
There were a couple of questions and challenges that needed to be addressed for this approach:
Imbalanced Index Sizes
Different customers have varying amounts of data in their indexes. For customers to get started, we initially create an index with a fixed number of shards and replicas, and have developed tools to split the indexes if a customer uploads a significant amount of data.
Data Duplication
File metadata that is common across customers will be duplicated across indexes. This turned out to not be an issue because analysis of files across customers showed that the vast majority of files were shared only for a few customers, and this increase in storage was a tradeoff we were willing to make for better performance, scalability and segmentation of customer data.
This added a layer of complexity to the search code, as we needed to ensure that duplicates were filtered out from multi-index queries. The indexing code needs to be able to update multiple indexes for files that were present in multiple environments.
Performance Evaluation – Improvement
Now that we have hypotheses, it is crucial that we validate them and test them carefully.
We have utilized esrally, a tool specifically designed for performance testing on real clusters.
The performance tests are constructed so that they are tailored specifically to actual queries that are used by customers and internal threat research teams. We sampled real queries and set up production-sized ECK clusters for the performance evaluation, which allowed us to simulate real-world usage as closely as possible. This is essential for the test results to be accurate and ensure the design meets the expected level of service in production.
The result of these tests revealed significant improvement in performance for multi indices design. We observed 20-50x improvement in search latency for individual customers. The improvement was particularly evident among smaller customers, who have less data. We’ve also observed better performance on more complicated such as wildcard, large boolean filters.
Other Improvements
Besides the index splitting design, we have also made other improvements considering the overall health of the Elasticsearch cluster.
Slow Queries
There were a few patterns of queries that ran much slower than others:
- Disjunction with several clauses: One particular query ran a disjunction over several fields, each checking for matches on several terms. We decided to move this logic into the indexing code and store the result directly as a field in Elasticsearch.
- Composite aggregations: With a large number of documents in a single index, supporting real-time, paginated aggregations was unrealistic. We were looking for a fast count-distinct query, and slightly approximate results were acceptable. We decided to precompute these using an algorithm like HyperLogLog++ and keep the results in a database for fast retrieval.
Indexer Rate Limits and Prioritization
Indexing and search compete for the same resources within a cluster. Since files can be uploaded at any time, indexing load is highly unpredictable, which in turn may affect our search latency SLOs.
Not all indexing updates are equal. Some metadata, like hashes, file sightings, upload time, need to be instantly searchable. Other data, such as analysis results, can tolerate a bit of staleness without much impact to customers. When push comes to shove, the search index being always up-to-date is far less important than search working predictably (or working at all!).
We decided to tradeoff data freshness for performance based on the data model and introduced prioritization and rate limiting in our indexing infrastructure. Prioritization ensures that key data is instantly searchable, while rate limiting ensures that the search stack doesn’t slow to a crawl when the indexing load is too high.
Conclusions
Cluster Nodes are Stateful
Indexing and search competing for the same cluster resources was the main challenge that pushed us to redesign our index. Elasticsearch is already working on separating compute and storage, which will bring several benefits.
- Indexing will consume resources independently from search, allowing them to be tuned separately, and enabling much larger ingest throughputs.
- Using object stores for index data will allow search to autoscale independently and without cluster rebalancing.
Fixed Shard Count Challenge
Choosing the number of shards at index creation time poses a big challenge for us. Since most of our customers grow continuously, we’ve had to build tools for splitting and migrating indexes. However, splitting requires making the index read-only, which is inconvenient. Data streams and ILM don’t help either because our documents aren’t written in time series, all our documents are “hot” and can receive updates at any time.
Future Work
Cross-cluster Replication
Given we’re prepared to trade off staleness for better performance, cross-cluster replication offers a promising solution to reduce the impact of indexing workloads on search queries. However, creating and managing a separate cluster incurs a cost penalty, so we’ll likely enable this in a limited fashion.
Search Relevance and Ranking
While this is true for most search use cases, a threat detection and response platform must surface the most relevant results at the very top. As our search corpus grows, we’re developing a better understanding of what’s important to our customers and threat researchers. We’re at the early stages of building relevance and ranking into our platform, and are hoping that Elasticsearch can serve as the foundation for this effort.
Summary
Stairwell has leveraged Elasticsearch to handle real-time searches and manage large volumes of data efficiently. Our journey to achieving multi-tenancy at scale required us to overcome numerous challenges and as a result, gain significant learnings.
Our efforts and approach were validated by substantial performance improvements across all of our customers. Continuous optimizations in our indexing and search infrastructure have further refined our system’s efficiency and responsiveness.
As we explore search relevance, ranking and other applications like vector search, we look forward to sharing our learnings and engaging further with the search community!



