Never let a server fall out of sync with a database
This blog article overviews how we at Stairwell have solved a very common communication problem of software development: making sure that we can make changes to our database without bringing down other systems which rely on it. We give context to why we think the problem is important enough to have a robust solution. Our solution that we have created involves integrating two tools together:
sqlboiler, an ORM toolbazel, a build system
We are sharing the code we’ve written to solve this problem and implement a similar solution in your own codebase. The code is located here: https://github.com/stairwell-inc/sqlboiler-bazel. The article will take you through a lot of the code in the repo, but it’s worth reading all of it closely for completeness. There are other interesting things we are doing in there that are beyond the scope of the narrative and aren’t highlighted directly in writing.
Context given, let’s begin.
The problem
A perennial problem of software development is that systems which rely on one another often fall out of sync. Different systems work in tandem with one another by establishing contracts; i.e. if you call a particular system with a particular payload you will get a particular result. Contracts between systems work well for a period of time, but the moment an external system makes a breaking change to the contract everything that depends on the established contract breaks. The owners of external systems need to communicate that their contract is changing. Consumers of that system need to know that they need to make updates or break. Unless the engineers at your company are incredibly diligent when a contract changes and audit’s the entire codebase, often code paths that need to be changed are missed.
This category of problem occurs more often than you think if you expand your definition of what it means for a system to be external. A database and a server that your business maintains are both external to one another when you think about it. These systems also rely on an established contract of communication between one another that can easily become out of sync. That is a Problem with a capital P.
A contract changing between systems is, effectively, a communication issue. One person or team may have a need to change the contract for a legitimate business purpose but be completely unaware of the impact that change may have throughout their broader organization. Effective communication is unambiguous, concise and intentional. When a team proposes changes to a schema, the team on the other side should know what must be done. The problem here is that it is inherently ambiguous what must be done when a schema is changed unless the entire codebase is audited. That is not only impractical, but it can deteriorate relationships between coworkers when something is missed and problems arise as a result. This is a problem worth solving.
Ultimately, the missing link is that external systems do not share a source of truth with one another. If they did, we could produce typesafe code which would cause the compiler to enforce that the systems never fall out of sync with one another. Unfortunately, database schemas are written in a different language (SQL) than any server which might want to call into the database.
The solution
Given that the problem statement is that external systems are hard to keep in sync with one another, let us now take steps to make these systems internal. We want these systems to both depend on a single source of truth. When that source of truth changes, we don’t want to communicate that change via human interaction. Instead, we want the communication of that change to happen to our compilers. Our trusty compiler is more than happy to perform an entire codebase audit for us to make sure that the change is safe.
To facilitate this, we need two things working in tandem:
- A tool which can consume our schema and generate an object relational mapping (ORM) in the language of our server.
- A build system which will enforce that our ORM is rebuilt whenever a change occurs to our schema.
Together, we remove ambiguity as to when we are augmenting our database in a way that is incompatible with what our server expects. We can be informed apriori about such a breaking change just from compiling our server. With information comes the power to plan accordingly. As a business, we can either opt to migrate our server at the same time and do a synchronous deployment or take a completely different course of action. Whatever action we take, we take pleasure that we have chosen our course rather than being surprised by a bad rollout.
Sounds great, right?
Lets dive into how we have achieved these guarantees at Stairwell.
Choosing the tools for the job
1) Choosing an ORM
To achieve the properties described above, we need an ORM which will use a database schema as input and output files in the language of our server. But it is not enough to simply output any golang files, our ORM needs to output code which is typesafe such that compiler errors will be generated when a breaking schema change is detected. Not all ORMs will make this guarantee.
At Stairwell, we choose to write all of our services in golang. Given that set of constraints listed above, we choose sqlboiler as our ORM of choice. To read more about why sqlboiler is a particularly good ORM, read all about it here.
2) Choosing a build system
Our build system needs to make guarantees that our ORM is up to date with our schema, otherwise we risk human error introducing the category of bugs we are trying to avoid. As a rule of thumb, robots tend to do things more reliably than humans.
To get this guarantee, we will need to restrict ourselves to build systems which have a graph representation of what inputs/actions are required to generate a particular set of outputs. To put it another way, we need a build system that is capable of running our ORM tool for us and knows to do so when our schema file changes.
Furthermore, our build system of choice would be even better if it was polyglot and supported multiple languages. Just because the servers we are writing today are written in golang, that doesn’t mean we want to tie our hands to that decision in the long term. From a business perspective, it’s important to us to be able to get the properties we are aiming for in any language we might need to utilize at a later point in time. If we spin up a new subteam at Stairwell which authors their code in Rust, we want that subteam to enjoy the same codebase guarantees as our other developers.
Stairwell’s build system of choice is Bazel. Bazel has all the properties described above and is quickly becoming an industry standard for companies trying to solve similar problems as the ones described in this article. See all the other companies using Bazel here.
Hooking up our build system to our ORM tool
This section outlines how to integrate the tools we’ve chosen above together. We have created a repo with all of the code we will reference throughout. You can check out that repo here: https://github.com/stairwell-inc/sqlboiler-bazel
Bazel is a hermetic build system. It does not rely on your host system having particular libraries or packages installed in order for it to build things correctly. Instead, bazel requires us to declare everything we need for our build to complete successfully so that it can provision those tools for us rather than having developers follow a very stringent getting started guide.
In order to compile our go server and generate ORM code for our database, we will need the following tools:
- A database (at Stairwell, we use
postgrescompiled from source) - Golang toolchain to compile go code
- Go dependencies required to perform code generation
sqlboiler- Golang
postgresdriver - Golang Bazel package for getting files from Bazel’s sandbox
These dependencies are declared in Bazel’s WORKSPACE file which you can see here: https://github.com/stairwell-inc/sqlboiler-bazel/blob/main/WORKSPACE
Now that we have everything we need, we need to link them together and generate ORM code from our schema. In Bazel, in order to make the build system run tools for you, you have to define something called a build rule.
A build rule requires us to define what is needed as inputs, what tool we are trying to run, and what outputs will be generated after running that tool. For example, Bazel’s go rule set, rules_go, defines two build rules: go_library and go_binary. go_library defines its input as go source files and other go_library for imported dependencies. It outputs a compiled output of the go sources. go_binary requires a go_library as input and produces a runnable binary as output.
Our input will be a schema.sql file as well as anything needed to run sqlboiler. Our output will be a compiled version of our ORM which we can import into our golang server. The dependency graph we’ve outlined will look like this:
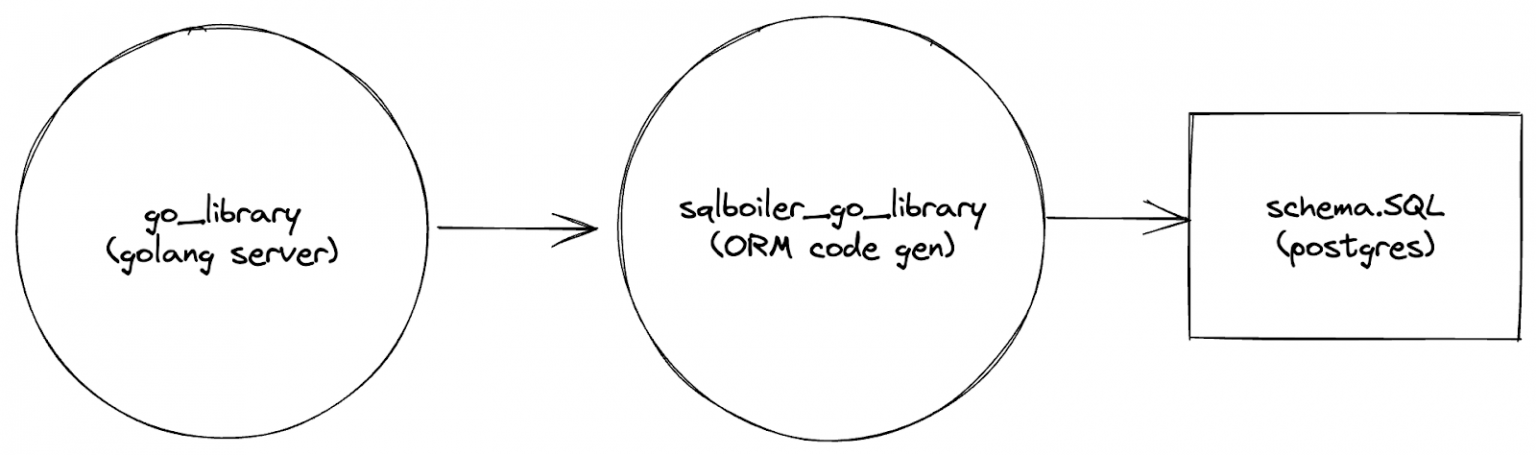
Our task then, is to create a build rule which runs sqlboiler and produces output that a go_library can depend on. We will name our particular build rule sqlboiler_go_library.
Writing a build rule: sqlboiler_go_library
When constructing a build rule, you first need to think about what that rule depends on in order to execute.
In our case, we will need sqlboiler to generate ORM code for to interact with our database in a typesafe way. sqlboiler, in turn, has a number of dependencies it needs to operate a database to interact with, so we also need to pull in postgres. In order to interact with postgres, sqlboiler will need a postgres golang driver. In order to perform a go compilation, we will need to bring in the go toolchain and whatever dependencies it needs as well so that we can compile successfully. Lastly, we will need to write a go binary of our own to orchestrate things: parsing command line flags from Bazel, setting up a psql instance, and running sqlboiler against said instance.
All of the above are dependencies that we know our rule will always need in any circumstance. In Bazel, we represent these types of things as default attributes to our build rule. Default attributes are ones that a user doesn’t have to define or configure.
Other attributes we need the user to set themselves. We need to know where their schema.sql file lives, what the import path of the go compilation should be and what configuration flags they’d like us to pass to sqlboiler.
After defining what attributes a rule requires, we need to actually use them and implement the rule’s execution logic. At a high level, a rule typically translates attributes into input files needed to perform an action and command line arguments to instruct the tool that it will run it feeds into the tool it’s running. The rule must also pre-declare what files the tool will output so that the build graph can be constructed without apriori to running the tool.
Additionally, we want our Bazel rule to be interoperable with go_library from rules go, so we will have to return all the metadata which go_library is expecting. Unfortunately, finding out what metadata a particular rule needs for interoperability usually means reading the source code directly. Since we know that go_library is interoperable with itself, we know that if we return the same providers it returns, we will also be interoperable. Reading the source, we can see that we will need to return three providers: library, source, and OutputGroupInfo.
For those curious, the actual implementation of the build rule can be found here: https://github.com/stairwell-inc/sqlboiler-bazel/blob/main/sqlboiler/sqlboiler_go_library.bzl
Consuming our build rule
Now that we have defined a build rule, we can generate ORM code for any schema that we have in our codebase. Whenever we want to interact with our database, we can just depend on that build target to make it available to the go compiler.
load("//sqlboiler:sqlboiler_go_library.bzl", "sqlboiler_go_library", )
sqlboiler_go_library(
name = "models",
create_users = [
"operator",
],
importpath = "github.com/stairwell-inc/sqlboiler-bazel/models",
schema = "powerplant",
sql = "//:schema.sql",
)
load("@io_bazel_rules_go//go:def.bzl", "go_library")
go_library(
name = "server",
srcs = ["server.go"],
importpath = "github.com/stairwell-inc/sqlboiler-bazel/server",
visibility = ["//visibility:public"],
deps = [
":models",
],
)The code above is how Bazel represents its build graph. We have schema.sql be an input to sqlboiler_go_library and have sqlboiler_go_library be an input to our server. Thus, we have created the dependency graph outlined in the beginning of this article.
Most importantly, the build rule that we defined is reusable. We have unlocked the ability to enforce type safety for calling into any number of databases we choose to maintain in the future.
Wrapping up
Hopefully this has been an informative journey into how code generation and a powerful build system can be utilized to solve communication problems you might encounter in a sufficiently large code base. In this example, we focused on keeping our server in sync with our database schema, but code generation can be used whenever you want to enforce a contract between two things that need to communicate with one another. So long as you have a single source of truth that disparate systems can reference, you can always utilize code generation to keep those systems in sync with each other.
The more guarantees you can provide between individuals or cross functional teams, the more effective they will be in working in tandem with one another. You can spend less time in large meetings to communicate riskier code changes when you can rest assured that your own compiler will alert you to potential problems that might come up.
At Stairwell, we are passionate about producing code that we can trust. We are passionate about building trust between each other. A crucial part of how we’ve built that trust is building upon a foundation of this type of guarantee in our codebase. If you enjoy solving complex engineering/communication problems like this one, take a look at our job openings here.
Thanks for reading!



