Scalable data processing with a distributed job scheduler
One of the Stairwell platform’s key features is the ability to continuously analyze files. Stairwell must maintain a constant state of analysis, even as the system ingests new files and YARA rules. In our last blog, we described the need for purpose-built systems which will be able to process petabytes of data every day. This blog explains how we redesigned our job-scheduling system to remove the database as a bottleneck, resulting in massive performance gains and the ability to scale to well over ten thousand workers.
Background: Job Orchestrator
Before diagram
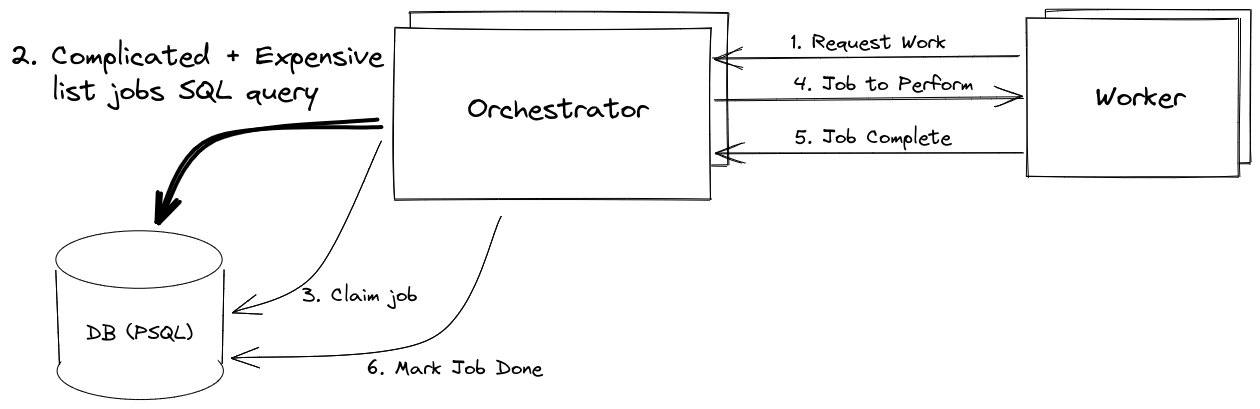
All Orchestrator replicas shared a single database (DB) instance. Prioritization logic was expressed in SQL. Listing jobs was expensive, and all operations (list jobs, claim job, complete job) went through the DB.
The Orchestrator is a job scheduling service that lives on Kubernetes. We have thousands of worker processes that request work. The Orchestrator uses PostgreSQL to store job state, determine outstanding work to be performed, and claim/lock jobs before assigning work to avoid duplicate work.
Additionally, scanning data at our scale — on public cloud infrastructure — is one of our major operational costs, which means optimizing scanning to lower costs is business-critical. One way to reduce costs is to ensure the Orchestrator is highly available. Otherwise, even a minute of downtime translates into hours of unutilized worker CPU time (e.g., 1 minute x 1000 workers = ~17h).
In a job scheduling system, the horizontal scaling of workers is bounded by what the job scheduler can support. Our initial Orchestrator used a PostgreSQL DB to store state. Unfortunately, the DB became a bottleneck sooner than anticipated and limited the number of worker nodes we could support. Another problem was the complexity of the SQL queries. The prioritization logic was expressed in SQL using self-JOINs, UNIONs, and NOT EXISTS to find rows that had not been attempted, or were ready for retries, ordered by various signals. The complexity of the SQL queries made it difficult to understand, maintain, and modify the Orchestrator prioritization logic.
With some back-of-the-envelope math, we determined that even if we 100x our data, the job state can comfortably fit in memory, giving us plenty of buffer to grow. And if that is not sufficient, it is possible to shard the data in order to horizontally scale the in-memory managed state – but let’s not get ahead of ourselves. We determined that managing the state in-memory would allow us to achieve much higher query performance as well as express the prioritization logic in Go rather than SQL. We are a Go shop, and as such, the engineering team has an easier time understanding and maintaining Go code. Another huge benefit is that Go is imperative, unlike SQL. That means we can reason and benchmark a program, whereas, with SQL, heuristics in the database’s query planner can arbitrarily change a query’s execution plan and as a result introduce variability into its performance.
Once we identified the issues with the existing DB-based Orchestrator and the new requirements, we determined that we could rebuild a replicated, highly available Orchestrator using Raft.
Raft managed state
Raft is a consensus algorithm. Consensus is used in fault-tolerant distributed systems to replicate state among a cluster of nodes. Each operation or state change goes through consensus, where a majority of the cluster needs to commit to the operation before it is applied. Raft was developed as an alternative to Paxos as an easier-to-understand consensus algorithm.
Rather than implement Raft ourselves from scratch, we opted to use etcd’s Raft implementation as it is well tested and used in many projects, such as etcd, Kubernetes, Docker Swarm, CockroachDB, Project Calico, and more.
After diagram
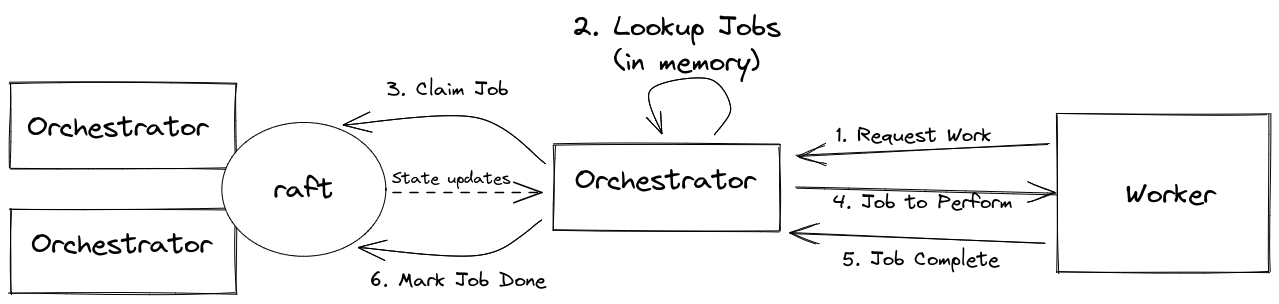
DB has been removed. All state lives in memory and is shared via Raft consensus. Job discovery happens in Go.
We replaced the SQL list jobs bottleneck by removing the DB altogether and moving the state into memory. The state is shared via Raft consensus and all application logic, including prioritizing jobs, lives in Go code. As before, the workers request work from one of the Orchestrator replicas. The Orchestrator determines a candidate job by introspecting the state in-memory, locks the job by notifying the other cluster nodes via Raft, and then assigns the work. Once the job is completed, the Orchestrator simply notifies the Raft cluster of the state change.
Challenges
Switching the Orchestrator to a Raft-based cluster had a number of challenges, a few of which we will share in this section.
K8s statefulset
Before, since all state lived in a DB, the Orchestrator nodes were stateless. As such, they were deployed as a traditional Kubernetes (k8s) deployment. With the state moving into memory and backed up to disk, we converted the Orchestrator to a statefulset in k8s. Statefulsets use persistent pod ids (orchestrator-0, orchestrator-1, etc.) which allows the nodes to discover and keep track of each other by pod id.
When an update is pushed, k8s replaces one pod at a time and thus keeps a majority of the nodes running at all times, which is required to continue accepting Raft state change proposals. Lastly, statefulsets can attach persistent disks which persist across pod restarts. The persistent disk is used to store the Raft write-ahead-log (WAL) and snapshots. Without it, when a node starts it would always need to obtain a full copy of the state from other cluster members. And if all nodes were to be shut off, the state would be lost.
Observability and debugging
One concern with switching to Raft was how easy or difficult it would be to debug issues, which is why we added an extensive amount of metrics. We discovered a bug in the etcd raftexample where if a Raft node dies at a particular point of execution, it could have stored a reference to a snapshot file that does not yet exist. If this occurred, the node would fail to restore its state on restart. It turned out this was a bug that was already fixed in etcd but had not been fixed in the example. We fixed the bug on our end and merged a PR it to etcd!
Careful state machine design
Storing and managing the state in memory with Raft is non-trivial and needs careful thought. There are classes of bugs that could cause state to diverge between nodes. This can happen when application code directly modifies state without going through consensus, or if state changes are non-deterministic. A non-deterministic state change would, for example, use `time.Now()` rather than a concrete timestamp. To mitigate these risks, we designed an FSM (finite state machine) interface and created extensive tests that apply state changes and compare snapshots of cluster members.
// FSM is a finite state machine.
// These methods must only be called by Raft.
type RaftFSM interface {
// Next triggers a state transition with an input.
Next(input []byte)
// Snapshot the FSM state. Raft persists the snapshot in order to compact the Raft log.
Snapshot() ([]byte, error)
// ApplySnapshot sets the FSM state from a previous Snapshot().
ApplySnapshot([]byte) error
}
FSM interface includes methods called by Raft.
// FSM implements RaftFSM interface.
// FSM stores shared state managed by Raft.
// Any state shared in the cluster must be updated via a Propose call to ensure the update is
// shared among all Raft nodes.
type FSM struct {
rn raftNode
// raftMu protects FSM state managed by raft.
// - Next() and ApplySnapshot() are the only methods that can hold the write lock for raftMu.
raftMu sync.RWMutex
// maps, structs, slices, containing the state, protected by raftMu, below…
}FSM struct implements the RaftFSM interface.
Validation
In order to validate and build confidence in the new job orchestration system, we continued to maintain the state in the DB as well as in–memory so we could compare the two. We collected metrics for the following:
- Counter of DB and in-memory disagreements (job is outstanding, job successfully locked, job marked as done)
- Number of total outstanding jobs
Monitoring these metrics confirmed that the Raft-based system never attempted an operation that was illegal according to the old DB-based system. Additionally, it confirmed that the in-memory state reflected the same work to be performed as did the DB.
Results
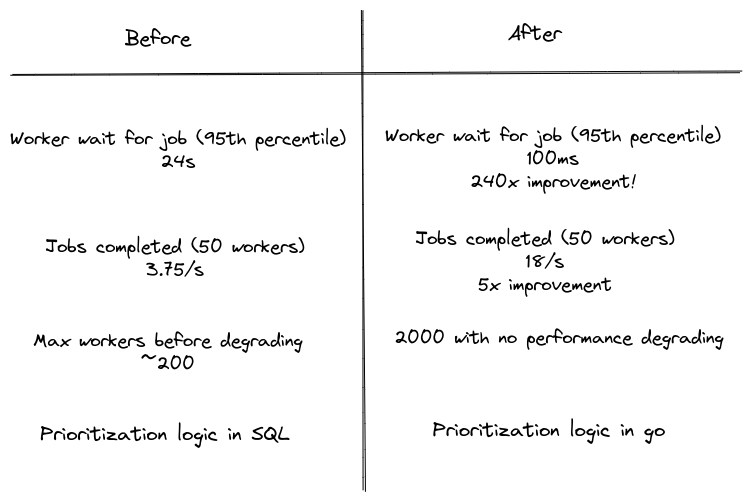
The Orchestrator today is more performant and much more reliable. Previously, worker job assignment time was 24s (p95). Today it is just 100ms (p95), which is a staggering 240x improvement! That translates into 5x the number of jobs being completed per second with the same number of workers. Previously the Orchestrator’s performance would start to degrade at around 200 workers, whereas today, we have been able to scale the workers to 2000 without performance degradation.
Before vs. after T-chart
Raft metrics for a 6h time period on April 27th, 2022.
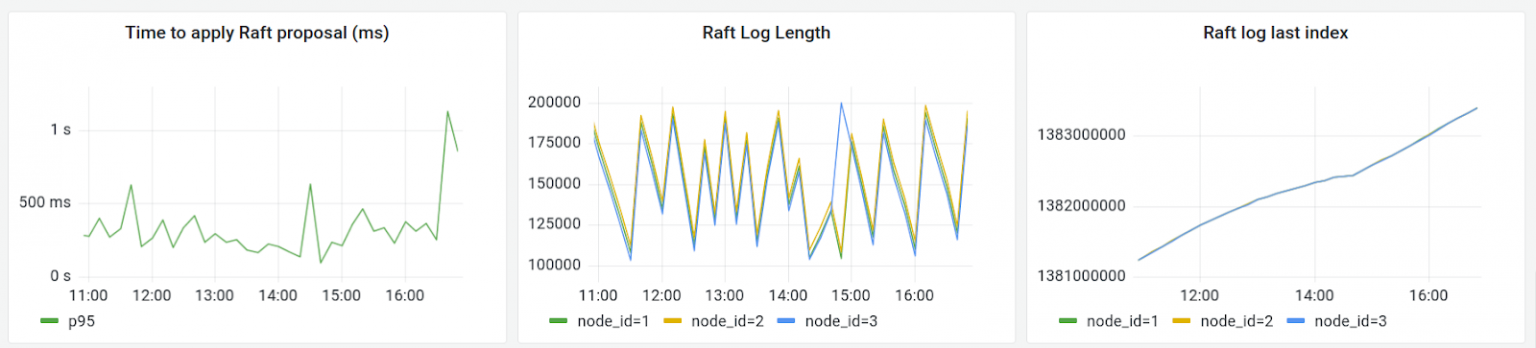
Left: 95th percentile latency for a proposed change to be applied to the Raft managed state.
Middle: Number of WAL entries. When the WAL reaches 100K entries, Raft creates a snapshot, which produces the zigzag graph.
Right: Total number of log entries on the Raft log over all time. Almost 1.4 billion operations have been performed to date.
In addition to the performance improvements we achieved at Stairwell, our pull request (PR) against the etcd-example was accepted, which will help the wider community avoid a bug we ran into.
Future work
We aim to make the Raft-based Orchestrator more cloud-compatible by moving snapshots from persistent disk to blobstorage (gcs), which will allow us to use existing tooling, greater snapshot visibility, and better backups. Additionally, we are working on building tooling for greater state introspection. Think SELECT in a DB, but for our in-memory state.
Given that the Raft-based Orchestrator has been stable, we are able to turn our attention to serious performance improvements, reducing costs, and new capabilities. A taste of what is to come:
- On-demand low-latency scans when a user is viewing/investigating a file
- Custom hardware optimized for scanning files in order to reduce costs
Final words
Building a distributed computation system with Raft has been very rewarding. Not often do opportunities arise to build your own distributed system. There are still many more exciting and challenging problems ahead, however, related to scaling, performance, low-latency serving, and batch and stream processing.
If you are interested in processing data at scale, want to learn more about the amazing engineering team, or our mission “Outsmart Any Attacker” resonates with you, email us at [email protected]! And if you’re worried about not having enough security experience for the job, check out our recent blog on why we value strong engineering skills from all backgrounds.



