

Why the Best Threat Hunting Tool Is Underused, and What Continuous File Intelligence Fixes
TL;DR
YARA remains one of the most practical and expressive tools defenders have for identifying malware, but most teams still use it only surgically. The limitation is not the language. It is the operating model.
YARA works best when it can run against the files that matter: the organization’s own preserved file history. Without that corpus, teams are left running rules against someone else’s malware collection or pushing broad scans to endpoints, where performance constraints, offline systems, limited history, and operational overhead make the process hard to repeat.
Stairwell is built to close that gap. Relevant files are collected into a private vault repository, preserved over time, and continuously evaluated as intelligence changes. New files are checked against existing rules. New rules are evaluated against historical files. Matches are connected to prevalence, related samples, analysis context, and investigative workflows.
A rule written today should be able to answer whether matching files appeared yesterday, last month, or before the threat was publicly known. That only works if the files were preserved in the first place.
Table of Contents
- The Problem With YARA Today
- Why YARA Got Stuck in Point-in-Time
- The Architectural Shift: Continuous File Intelligence
- What “YARA at Ludicrous Speed” Actually Means
- Custom Rules Inside a Private Intelligence System
- The Shared Library and What It Means From Day One
- From Match to Investigation
- Rule Hygiene Without Alert Fatigue
- Threat Reports: From Published Intel to Confirmed Status
- Known vs. Unknown: YARA and Variant Discovery
- Frequently Asked Questions
The Problem With YARA Today
YARA is valuable because it describes the file itself.
Hashes break when a file changes. Filenames lie. Vendor labels vary. Telemetry can tell you something ran, but not always what the file is or how it relates to other files. YARA operates closer to the evidence. It lets researchers describe what matters inside a file: strings, byte patterns, structural traits, metadata, and logic.
That makes YARA useful for malware research, threat hunting, incident response, and detection engineering. A good rule can identify durable traits across related samples, even when hashes differ.
The hard part is not writing YARA rules. It is running them well, against the data that actually matters. Most teams have two imperfect options.
They can run YARA against a public or third-party malware corpus. That helps with research, but it does not answer the enterprise question: did this appear in our environment?
Or they can push YARA to endpoints through an EDR or enterprise management tool. That can work for narrow response actions or targeted hunts, but it becomes painful for broad scanning. Large rule sets, full-disk scans, offline machines, endpoint performance concerns, and limited history make that model hard to repeat.
So YARA often becomes an emergency tool instead of a continuous intelligence layer. The questions defenders actually need to answer are specific:
- Did our users download this?
- Did our endpoints execute it?
- Did a related variant appear here six months ago?
- Did we see it before the advisory dropped?
- Can we show that our preserved file set does not match these rules or indicators?
To answer those questions, YARA has to run against the organization’s own files. More importantly, it has to run against files that were preserved before the rule existed. That is where most YARA programs break down.
Why YARA Got Stuck in Point-in-Time
YARA was designed to inspect file content, but many security architectures were not built around durable access to files. They were built around telemetry, logs, alerts, and events.
That mismatch is the first reason YARA often gets stuck in point-in-time use.
Logs can describe what happened, but they do not necessarily preserve the file. YARA needs the file. If the file is not available, the rule has nothing to inspect. Teams then have to rebuild a separate file layer, rely on whatever still exists on endpoints, or accept partial evidence.
The second issue is retention. Even when files are collected, many systems do not preserve them long enough for future intelligence to matter. Threat intelligence is rarely complete the moment a file first appears. A sample may be unknown when it enters an environment. A campaign may be named weeks later. A YARA rule may not exist until researchers understand which traits are stable. If the file is gone by then, the opportunity is gone with it.
The third issue is endpoint execution. Endpoints are not a durable corpus. They are laptops, servers, workloads, and user devices with performance constraints, inconsistent availability, and limited history. Running YARA broadly across them can be slow, incomplete, disruptive, and operationally expensive. Many teams learn this once and do not repeat the experiment.
Together, these constraints turn YARA into a project. Someone allocates a hunt window, chooses a limited set of rules, runs them against a limited slice of data, triages the findings, and moves on. Then a new advisory drops, and the process starts again. The language is continuous but the operating model is occasional.
The Architectural Shift: Continuous File Intelligence
The fix is not simply faster scanning. The fix is preserving the right corpus first. Stairwell starts from a different assumption: preserve the enterprise file history, then make intelligence continuously applicable to it.
Relevant files are collected into a private repository. Once stored, they remain available for future analysis. YARA rules can then run centrally against that preserved file history instead of relying on public corpus matching or repeated endpoint scans.
The operating model is simple:
- New files are evaluated against existing rules.
- New rules are evaluated against historical files.
- Matches are tied to file context, prevalence, related samples, and analysis.
- Analysts can pivot from a match into investigation.
This changes what a YARA rule means. In a traditional model, a new rule is mostly a future-facing detector. It helps catch the next thing. In Stairwell, a new rule also becomes a historical question:
Have we ever seen this before?
That is the core difference. Preserved file history lets defenders apply new understanding backward. That matters during incident response, advisory response, threat hunting, and executive reporting. A rule written today can be evaluated against files collected before the rule existed, then continue matching against new files as they arrive. That is what makes YARA operational threat intelligence instead of occasional.
What “YARA at Ludicrous Speed” Actually Means
The phrase is brand language but the substance underneath it is architectural. YARA at scale should not mean running bigger endpoint scans or checking more rules against someone else’s corpus. It should mean running YARA continuously against the file history that matters most: which is your own.
That requires three things:
- A private, durable corpus of enterprise files.
- Continuous evaluation of new rules and new files.
- Context that turns matches into investigations.
In many environments, YARA is slow because the scan model is slow. Teams have to locate files, queue jobs, wait on endpoints, deal with offline machines, and run rules against data that may or may not still exist. Stairwell changes the scan model by centralizing analysis against preserved files. The endpoint component collects relevant files for analysis. The repository performs the historical scanning.
That distinction matters. Broad YARA scanning does not need to run repeatedly on endpoints. Endpoints have performance constraints and limited history. The durable repository or private vault has the files, the context, and the ability to apply new intelligence backward. The result is not just speed, but repeatability.
Adding a rule should not require a bespoke hunt. Applying a public report should not require days of scan planning. Asking whether a file appeared before the advisory should not depend on whether an endpoint still has the file. When the file history is preserved and analysis is continuous, every new rule becomes more than a detector for tomorrow. It becomes a way to interrogate yesterday.
Custom Rules Inside a Private Intelligence System
YARA programs usually combine public research with internal detection logic. Public rules help teams move quickly when new campaigns, malware families, or advisories are published. Internal rules may encode proprietary research, environment-specific knowledge, or sensitive indicators a team does not want to expose. Stairwell supports both.
A shared rule library provides immediate coverage for known malware families and common threat patterns. Customer-uploaded rules can remain private while still running against the customer’s preserved file history.
That privacy matters because good YARA rules are often intellectual property. A team may spend years building internal detections for a specific actor, malware family, or operational pattern. Those rules should be operationalized without turning them into shared artifacts.
In Stairwell, customer-uploaded rules can remain private to that customer’s environment. They do not need to become part of a shared rule library to be useful. The principle is straightforward: your files stay private, and your detection logic should be treated with the same care.
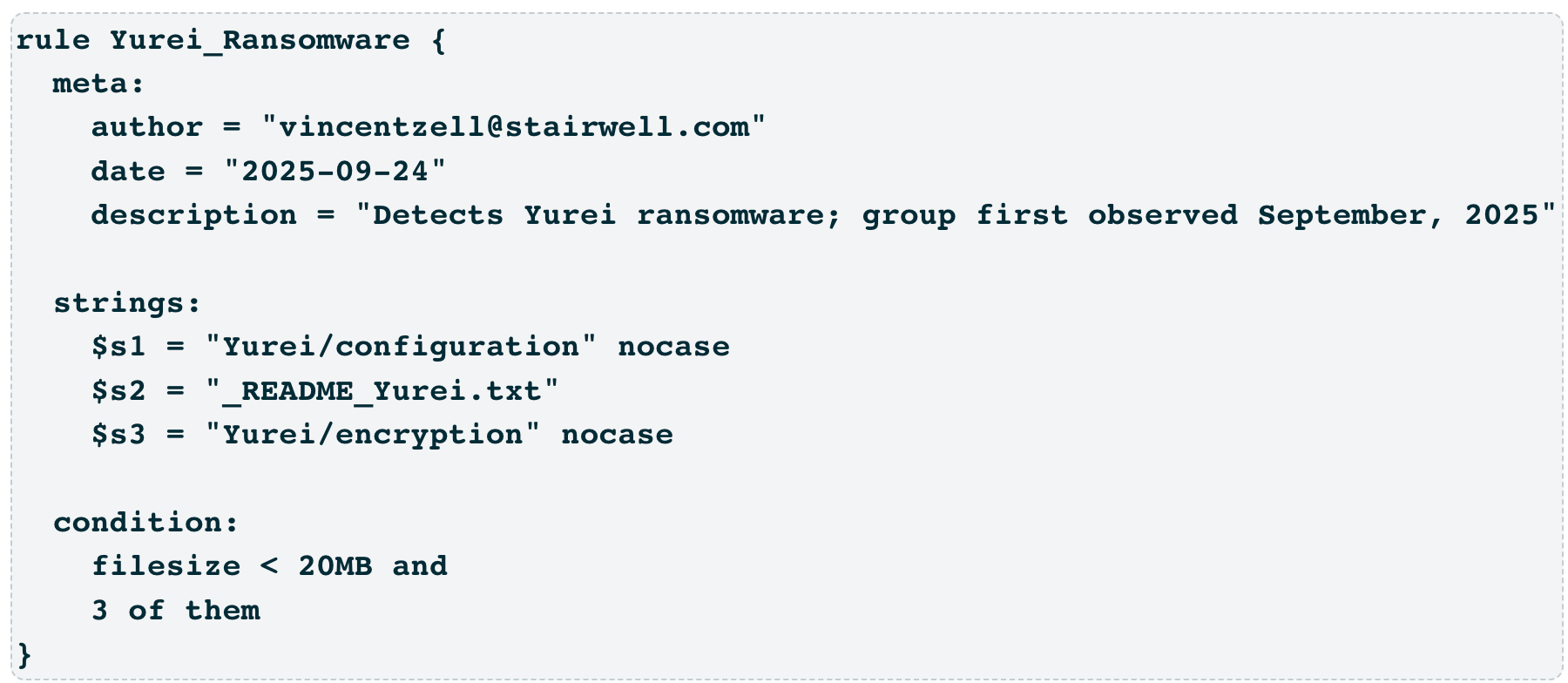
Yurei Ransomware YARA rule — example of a custom rule codifying stable traits of a malware family
The Shared Library and What It Means From Day One
A mature YARA program does not start from zero. Shared rules help defenders move quickly when new campaigns, malware families, and advisories are published. They give teams immediate coverage for known malware families and common threat patterns, while private rules let each organization specialize around its own environment and research.
In Stairwell, the shared rule library exists to make YARA useful from the beginning. As files are collected into the private vault repository, they can be evaluated against existing rules. As new research becomes available, new logic can be applied to preserved file history. This is the key distinction: shared detection content is not only future-facing. When paired with preserved file history, it can also answer historical questions.
Stairwell Rules library — active rule sets including shared Threat Report Feeds and curated detections
A newly published rule can help determine whether matching files appeared before publication. A new advisory can be evaluated against files already collected. A new malware-family rule can identify older samples that were not understood at the time they first appeared.
YARA rule users also need flexibility. Public or shared rules are useful, but they may not fit every environment exactly. Teams may want to adapt a rule, narrow it, broaden it, or codify a variant of their own. The ideal model preserves the value of shared coverage while allowing private specialization.
From Match to Investigation
A YARA match should not create another orphaned alert. A match answers one question: this file satisfied this rule. Analysts still need to know what the file is, where it appeared, how common it is, whether it resembles other samples, and what to do next.
That is why Stairwell connects YARA results to file intelligence. A match can be viewed alongside prevalence, static and behavioral analysis, related samples, threat reports, and investigative pivots.
The goal is to reduce the distance between detection and decision. A YARA hit becomes the starting point for scoping and triage, not the end of the workflow.
Useful context includes:
- Prevalence inside the organization’s environment.
- Related samples and similarity-based pivots.
- Static and behavioral analysis.
- Associated threat reports or indicators.
- The systems, users, or timeframes connected to the matched file.
That context changes how a match is interpreted. A hit on a rare executable seen on one machine is different from a hit on a common file present across the fleet. A hit connected to a public advisory is different from a hit on an internally developed tool. A hit that belongs to a cluster of related samples is different from a single isolated match.
The value of YARA is that it provides the rule logic. File intelligence provides the decision context.
Rule Hygiene Without Alert Fatigue
Continuous YARA only works if the rules behave well. A noisy rule running occasionally is annoying. A noisy rule running continuously against a large file corpus can create noise at scale. That means rule quality, testing, and context are essential.
There are three practical requirements. First, teams need a way to validate rules before relying on them operationally. A rule should be tested against known-good and known-bad samples whenever possible, so obvious false positives are caught before the rule becomes part of the workflow.
Second, teams need control. Rules should be adjustable, pausable, and refinable without losing the underlying detection logic or forcing analysts to delete work they may need later.
And third, matches need context. A YARA hit alone is not the alert. The hit plus surrounding evidence is what matters.
Context includes prevalence, related samples, static and behavioral analysis, and the investigative picture around the matched file. That is what helps analysts decide whether the rule match represents a real threat, a benign internal artifact, a tool that requires exception handling, or a lead that needs deeper investigation.
This is what makes YARA usable at scale instead of overwhelming. Rules become higher fidelity not only because they are written well, but because their output is interpreted alongside the evidence.
Threat Reports: From Published Intel to Confirmed Status
Public advisories and threat reports often include hashes, domains, IPs, YARA rules, and behavioral details. The operational question is simple: Does any of this apply to us?
Without preserved file history, that answer requires manual extraction, scan planning, endpoint queries, partial evidence, and caveats. Teams have to extract indicators, import or write rules, set up scans, wait for results, and then explain what the results do and do not cover.

WinRAR CVE-2025-8088 detection rule — example of a published-intel rule that can be evaluated against preserved file history
With a preserved file corpus in a private vault, those rules and indicators can be evaluated directly against the files the organization has actually seen. Matches can be scoped to affected files, systems, and timeframes. Non-matches can be reported as non-matches across the preserved file set.
That last phrase matters. This is not a claim that nothing bad exists anywhere. It is an evidence-based statement about the files available for analysis. That precision is what makes the answer useful.
Public research stops being something teams only read. It becomes an environment-specific answer. The organization can identify matching files, scope affected systems, or report that the preserved file set did not contain matches for the provided logic. This doesn’t happen eventually after a bespoke hunt. It is part of the normal analysis model.
Known vs. Unknown: YARA and Variant Discovery
YARA and similarity analysis solve different parts of the same problem. YARA is best when defenders know what they want to describe. A rule names the strings, byte sequences, structural traits, metadata, or logical conditions expected in a file. It is precise, auditable, and useful for codifying known traits.
Similarity analysis is useful when defenders have a sample and want to find files that look related, even if no rule has been written yet. The two approaches reinforce each other. A YARA match can seed a search for related variants. A cluster of similar files can reveal stable traits worth turning into a new YARA rule. That new rule can then run across preserved file history.
This is especially useful for repacked, re-signed, or modified malware. A single rule may not catch everything. A single similarity search may not be precise enough. Together, they create a loop:
- Find a suspicious or known file.
- Identify related samples.
- Codify stable traits in a YARA rule.
- Re-scan preserved file history.
- Continue evaluating new files as they arrive.
That loop becomes much more valuable when it runs against the organization’s own historical file corpus. A detection program built only on YARA catches what has been explicitly described and may miss what has not yet been codified. A program built only on similarity can surface related files but may lack the precision and auditability YARA provides. Used together, they help defenders cover both the known and the related unknown.
Frequently Asked Questions
What is YARA used for in cybersecurity?
YARA is used to identify files based on patterns such as strings, byte sequences, metadata, structural traits, and logical conditions. Malware researchers and defenders use it to detect malware families, threat actor tools, suspicious files, and related variants.
Why is YARA hard to operationalize?
YARA is hard to operationalize because many teams either run it against third-party malware repositories, which are not their environment, or run it directly on endpoints, which can be disruptive and hard to repeat broadly. YARA needs access to file content, and many security systems do not preserve a durable file corpus for historical analysis.
What does YARA at scale mean?
YARA at scale means running YARA rules continuously against a durable corpus of relevant files, including historical files. For an enterprise, that corpus needs to include its own file history. The goal is not just larger scans. The goal is continuous evaluation of new files and new rules against the data that matters.
How is running YARA in Stairwell different from VirusTotal?
VirusTotal and similar services are useful for checking rules against public or third-party malware collections. Stairwell is focused on running YARA against the enterprise’s own preserved file history inside a private vault, so teams can answer whether matching files appeared in their environment.
Why not just run YARA through EDR?
Running YARA through EDR can work for narrow response actions or targeted hunts. It is less practical for broad, repeated, historical analysis because endpoint scans can be resource-intensive, incomplete, and disruptive. Stairwell centralizes YARA scanning against preserved files instead of repeatedly pushing broad scans to endpoints.
Can YARA rules run retroactively?
Yes, but only against files that have been preserved. Stairwell stores enterprise file history so newly added YARA rules can be evaluated against files collected before the rule existed. The same rule continues matching against new files as they arrive.
How many built-in rules ship with Stairwell?
Stairwell provides a shared rule library that gives teams immediate coverage for known malware families and common threat patterns. Stairwell ships a curated library of more than 80,000+ YARA rules maintained by Stairwell’s Threat Research team and supplemented by the broader research community.
Does Stairwell run YARA on endpoints?
Stairwell’s broad YARA scanning runs centrally against preserved files, not repeatedly on endpoints. The endpoint component collects relevant files for analysis; the repository performs the historical scanning.
Are custom YARA rules private?
Yes. Customer-uploaded YARA rules remain private to that customer’s environment. They do not need to become part of a shared rule library to be operationalized.
Can YARA matches feed our SIEM, SOAR, or ticketing system?
Stairwell exposes an API and integrates with the platforms security teams already operate, including SIEM, SOAR, and case management workflows.
How does Stairwell prevent low-fidelity rules from creating noise?
YARA at scale requires rule hygiene. Rules should be validated before deployment, refined when they create noise, and interpreted with context. A YARA hit alone is not the alert. The hit plus surrounding evidence is what matters.
Can rules from public threat reports trigger automatic retroactive scans?
When a report includes YARA rules or indicators, those can be evaluated against preserved file history. Teams can identify matching files, scope affected systems, or report that the preserved file set did not contain matches for the provided logic.
How do YARA and similarity analysis work together?
YARA finds files that match explicit rule logic. Similarity analysis finds files that resemble a known sample. A YARA match can seed similarity analysis, and similarity results can inform new YARA rules. Together, they create a loop: find, relate, codify, and re-scan.
What should teams look for in a YARA-at-scale architecture?
Teams should look for three capabilities:
- A private, durable corpus of enterprise files.
- Continuous evaluation of new rules and new files.
- Investigation context that turns matches into decisions.
YARA remains the language. The corpus and operating model are what determine whether the program becomes continuous or stays occasional.